Decision Tree Classifier in Python
For my Computer Science build week with Lambda School, I had the option to build from scratch a machine learning algorithm from a list of options. I chose to do this project on Decision Tree Learning, with a decision tree classifier.
What is Decision Tree Learning?

Decision Tree Learning is a predictive modeling approach using statistics and machine learning, commonly used in data mining. Decision trees use observations from different features in a dataset and their relationship with a target variable in order to try to “make sense of what’s going on.” Decision trees can come in the form of classification models, used for categorical (discrete) variables, to classify the target variable based upon the input of the features into the model (such as classifying a type of animal, or whether or not a patient may have cancer). They can also take the form of regression models, which are used for numerical (continuous) variables, such as pricing predictions.
Decision trees are made of nodes— the root node, from which all other nodes stem out of, branch nodes, which act as decision points to determine how to best split the data to “make sense of what’s going on.” These decision points can be calculated using a variety of metrics.
Decision Trees also have leaves, also known as terminal nodes, which hold the predicted outcome based upon what the model has learned.
What are Entropy and Information Gain?

Entropy is a measure of disorder within our data, and is calculated using the formula above, where p is the occurrence of an element within the distribution of our available classes.
Information gain is a metric that tells us how well an attribute divides the training data into our different classes. Without getting too statistical or heavy into the actual calculations, we first calculate our original (“parent”) entropy, and calculate the weighted average of the entropy of our children. Our information gain is then calculated by subtracting this value from the parent entropy.
My Decision Tree Classifier
My decision tree classifier algorithm utilized two classes — The first was the Node class, and the second was my Classifier class.
The Node class simply stored the left direction, right direction, best feature and threshold to split upon, and if it was a leaf node, would store a value. It also included a single method:
- .is_node_leaf()
which returned the value stored within our node, assuming one existed (meaning it was a leaf).
The Classifier Class
The Classifier class contained two main methods:
- .fit()
- .predict()
in addition to a variety of helper functions:
- _make_split()
- _find_best()
- _what_splits()
- _calculate_entropy()
- _calculate_information_gain()
- _most_common()
- _make_prediction()
.fit(X, y)
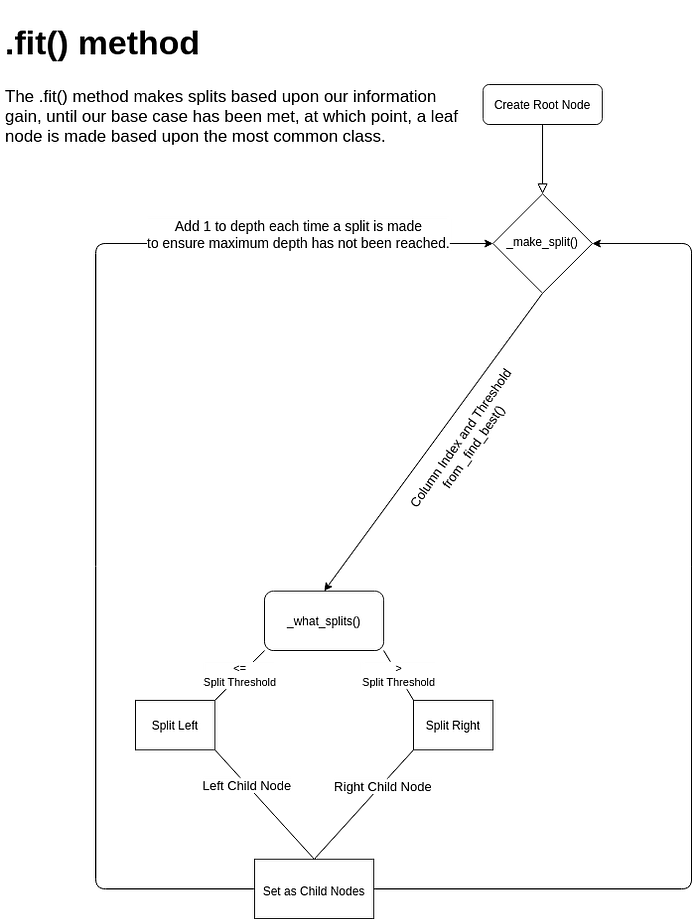
The .fit() function in my Classifier class creates the root node, and begins the splitting process of determining which splits should be made where based upon the information gain calculated in ._calculate_information_gain().
.predict(X)
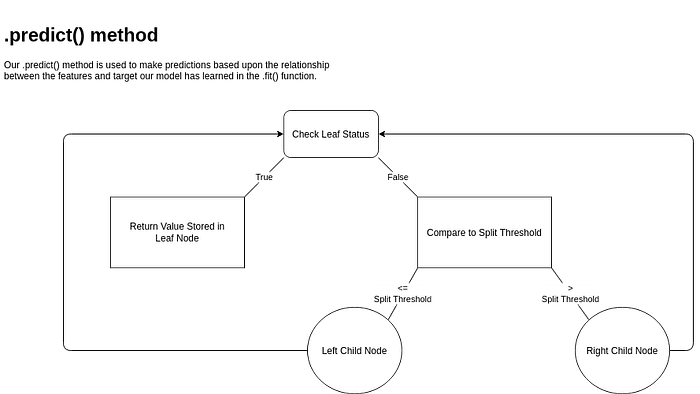
The .predict() function in the Classifier class makes predictions based upon the input, from the relationships it has learned in the fitting process. In order to do this, I called the ._make_prediction() helper function, which traverses down the decision tree, comparing our feature to the split threshold, and made predictions for each feature in our input.
Helper Functions
._make_split(X, y, depth=0)
The ._make_split() helper function is used to grow the decision tree. The method starts by ensuring the base case of maximum depth had not been reached, and that there was more than 1 class to predict. If there wasn’t, I made a leaf with the value calculated in my ._most_common() helper function.
If the base case had not been met, I selected an array of random indices based upon the number of features in our data. This was to be used in a greedy search in .find_best() according to information gain calculations. The left and right indices were then determined using the _what_splits() method, and splits were recursively made from these child nodes, until the base case was met. In order to do this, I added 1 to our depth each time a split was made.
._find_best(X, y, feature_indices)
This helper function helps us find out the best possible split based upon our information gain. In order to do this, I iterated through our array of feature indices and calculated the information gain using the _calculate_information_gain() helper function. If the calculated gain was more than the gain we currently had, the best available gain would be re-defined, as well as our split index and threshold. After the array has been iterated through, we will have our best information gain, and can return its related index and threshold.
._what_splits(X, split_threshold)
This helper function of the Classifier class determines the left and right indices, left being the point where X is less than or equal to our split threshold, and right is defined where X is greater than our split threshold.
._calculate_entropy(y)
This helper function of my Classifier class calculates entropy using the following formula:
-np.sum([p * np.log2(p) for p in ps if p > 0])
Where ps is an array of values based upon the number of occurrences of each class, divided by the total number of classes.
._calculate_information_gain(X, y, split_threshold)
This helper function calculates the information gain using the logic mentioned above. It calculates the parent entropy by simply calculating the entropy of the entire target vector. It then determines the left and right indices using the ._what_splits() helper function, determines if information gain is even available, then continues the calculations, with the left and right entropy being calculated by applying the fetched indices to our target vector.
._most_common(y)
The ._most_common() helper function of my Classifier class was used to determine the most common value in our target vector.
._make_prediction(X, node)
The ._make_prediction() function of my Classifier class is used to recursively traverse down the decision tree until a leaf node is met. When the node reached is a leaf node, we’ll return its value as our prediction.
How to Use My Decision Tree Classification Algorithm
To use my Decision Tree Classifier, you’re going to need a dataset for classification. I’m using Scikit-learn’s built-in breast cancer dataset for my example.
I’m going to need to import my dataset, as well as my Classifier algorithm. Note that the decision_tree.py script is in the same folder I’m working in.
Next, we need to do a train-test-split. This means that we’re splitting the data into two separate parts — one for “training” (for the model to learn off of; this is used during the fitting process), and one for “testing” (making predictions, and evaluating model performance based off the respective metric; in our case, accuracy). Because the build week requirements were related to the algorithm, I chose to use Scikit-learn’s train_test_split. There are a variety of different options for train/test distribution of data, but in our case, we’re going to stick with 70/30.

Note that we are using the variables X_train, X_test, y_train, and y_test. This is to differentiate our features (X) and our target (y), as well as which set of data it is being used for — training or testing.
Now, it’s time to instantiate our model, and fit it to our training data. This is done by inputting the features and target (X, y) from our training data as such:

Now that we’ve fit our model, we also need to store the predictions made from our features from our testing data. This is so we can evaluate our model’s performance, by comparing it to the actual values in our test data (y_test).

Comparing Results With Scikit-Learn

Upon comparing results between my algorithm and Scikit-learn’s decision tree classifier, I confirmed that I was able to get similar accuracy to Scikit-learn’s algorithm, using Scikit-learn’s built-in wine dataset.
I enjoyed this build week, and have had a lot of fun working on this! I look forward to continuing to expand my knowledge on Computer Science in the upcoming unit!
